
FiddleCube 帮助开发人员使用合成数据微调和部署大型语言模型 (LLM)。我们利用 AI 为想要自定义 LLM 但没有资源创建用于微调和强化学习的带标注的训练数据集的客户生成私有的高质量数据集。
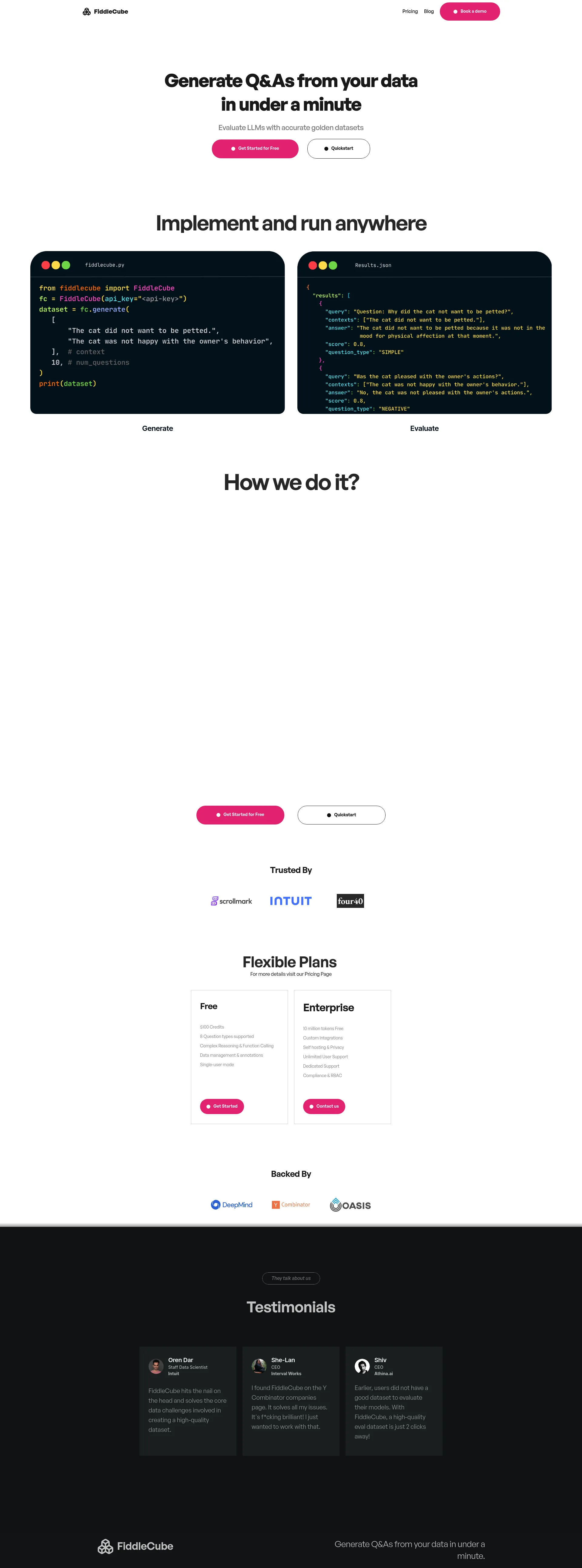
FiddleCube 受领先的数据科学家和 AI 专业人士的信赖。我们的平台旨在解决核心数据挑战,并简化高质量数据集的创建。加入这场革命,使用 FiddleCube 提升您的 AI 训练。

用于训练 LLMs 的精选数据
为基于 LLM 的应用程序添加推理能力

构建可访问的本地 AI。

发布可靠 LLM 代理的平台,速度提高 10 倍。

用于检索增强生成的 API

满足所有生产需求的全栈 LLMOps 平台

LLM 团队的 Gitlab

认识 Tara AI,您全新的工程效率副驾驶。

用于医疗保健的 AI 工具和 LLM

无代码 LLM 应用程序/工作流程构建器

与志同道合的专业人士进行一对一对话

从 Slack 混乱到清晰,只需几分钟

在不到 30 分钟的时间内个性化数千个着陆页

首个用于文档解析的 LLM,兼具准确性和速度

面向 SaaS 专业人士的 AI 助手

带实时翻译功能的 AI 电话应用程序

令人愉快的 AI 支持的互动演示—现在无需登录

AI 动态图形副驾驶

抛洒彩带,摆脱压力和焦虑,100% 无需人工智能

SaaS 的顺畅支付