
Xylem AI is a multi-cloud software stack for fine-tuning and inferencing open-source LLMs. We abstract away the training + inferencing infrastructure and the tooling/CI-CD around it, enabling data/ML teams to leverage all the optimisations on their VPC as docker containers for one-click deployments. Think of it like a hyper-optimised Sagemaker + Bedrock that is not restricted to only AWS. It can work with VMs from any cloud provider and integrate with any storage solution/data lake.
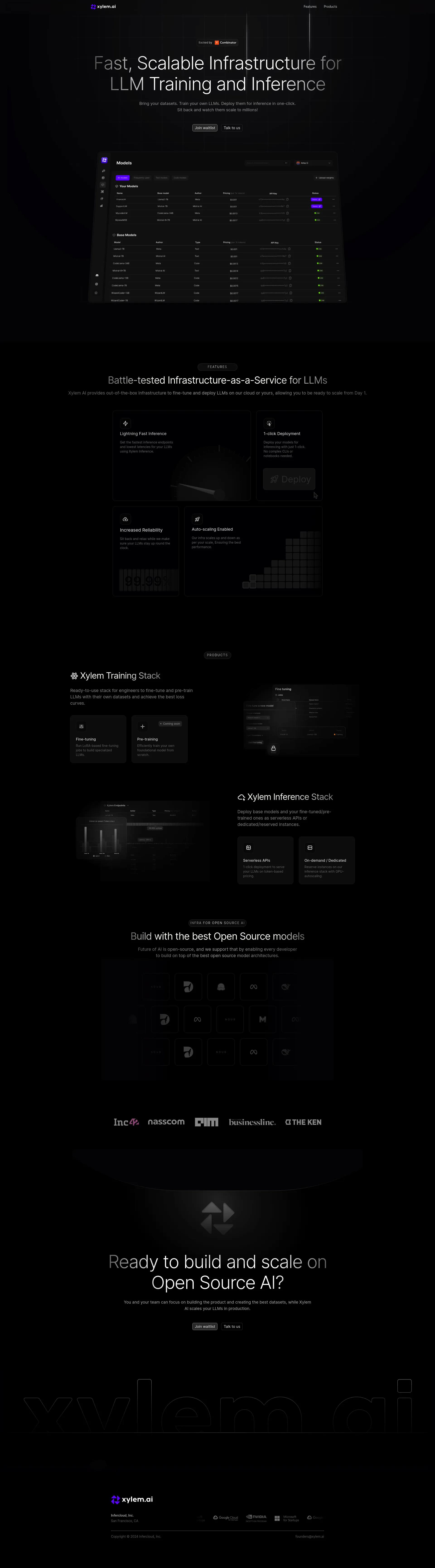
Pipeshift AI provides out-of-the-box infrastructure for fine-tuning and inferencing open-source LLMs, allowing you to be ready to scale from Day 1. Bring your datasets, fine-tune multiple LLMs, and start inferencing with one-click.
Pipeshift AI offers flexible pricing models:
Pipeshift AI is backed by Infercloud, Inc., based in San Francisco, CA. Our team is dedicated to providing the best infrastructure for fine-tuning and inferencing open-source LLMs, ensuring you can focus on building the best AI applications and agents.

Data-Centric Co-Pilot for Computer Vision Engineers

Open-source, AI-assisted LLM fine-tuning library for non-AI developers

The Operating System for Edge Computing

Save, migrate and resume compute jobs in real-time

Run serverless GPUs on your own cloud

Low latency API to run and deploy ML models

Heroku for AI

The platform to ship reliable LLM agents 10x faster.

Database for AI

The First Cloud Platform for Firmware Development and Testing

Match with like-minded professionals for 1:1 conversations

Go from Slack Chaos to Clarity in Minutes

Personalize 1000s of landing pages in under 30 mins

The first LLM for document parsing with accuracy and speed

AI Assistants for SaaS professionals

AI-powered phone call app with live translation

Delightful AI-powered interactive demos—now loginless

AI Motion Graphics Copilot

Pop confetti to get rid of stress & anxiety, 100% AI-free

Smooth payments for SaaS